
New discoveries #13
Multiple Field-of-Views Segmentation, Hugging Face, Location-based species presence prediction, AI for Social Good, FireRisk dataset, Lightning 2.0 & Google Dataset Search

Welcome to the 13th edition of the newsletter. I'm delighted to announce that the newsletter now has 4k subscribers 🔥
Multiple Field-of-Views Segmentation

Satellite image segmentation has a wide range of applications, but current approaches to processing these large, high-resolution images typically require downsampling and cropping which inevitably decreases the quality of segmentation. To tackle this challenge, researchers developed MFVNet, a deep adaptive fusion network that considers multiple field-of-views (FOVs) in satellite images.
MFVNet uses pyramid sampling to obtain images at different scales, capturing both large spatial contexts and finer details. It then selects scale-specific models to make the best predictions for each scale. After that, the output feature maps and score maps are aligned using a scale alignment module, which overcomes spatial mis-registration among different scales. Finally, an adaptive fusion module generates weight maps that help fuse the aligned score maps, producing a final, segmented prediction.
By employing this approach, MFVNet maintains both the overall context and fine details of satellite images, leading to more accurate segmentation. The performance of MFVNet surpasses previous state-of-the-art models on three typical satellite image datasets, demonstrating its effectiveness in satellite image segmentation.
Hugging Face

Hugging Face is a company that focuses on enabling collaborative open source machine learning by providing libraries and a platform where the community has shared over 150k models, 25k datasets and 30k ML demos. The company is well-known for its open-source work on libraries such as Transformers, Gradio, and Datasets. This post highlights some of the remote sensing specific activity that has taken place recently.

Following the recent earthquake in Turkey, a collaborative effort emerged within the community to utilise machine learning and remote sensing imagery for evaluating building damage. Initially, the community gathered on a Discord server; however, they then opened a Hugging Face organisation account, where they collaborated through pull requests to develop ML-based solutions. This endeavour involved the fine-tuning of various models, such as YOLO, EfficientNet, SegFormer, and other models. Read more about this effort in the blog post: Using Machine Learning to Aid Survivors and Race through Time
Fine tuning CLIP with Remote Sensing (Satellite) images and captions demonstrated the fine tuning of CLIP for captioning remote sensing imagery. The trained models are open-sourced on Hugging Face here, and here is also an online demo here
Hugging Face is also an increasingly popular place for hosting open source datasets, owing to its straightforward API and fast & reliable downloads.
https://huggingface.co/datasets/keremberke/satellite-building-segmentation
https://huggingface.co/datasets/alkzar90/rock-glacier-dataset
Competition: Location-based species presence prediction
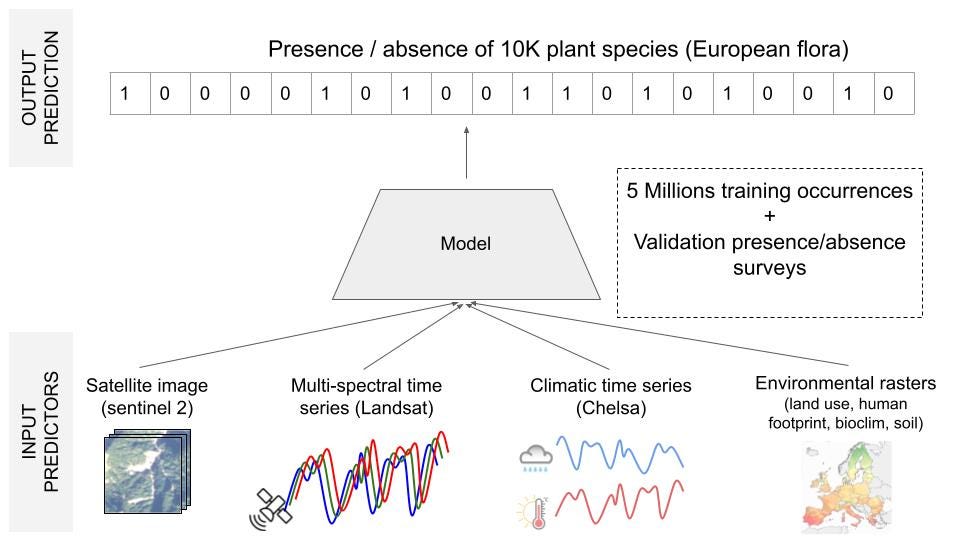
This competition invites participants to develop a system capable of predicting plant species present in a specific location at a given time. Such a system has potential applications in biodiversity management, conservation, and enhancing species identification tools like Pl@ntNet.
The core technical challenge involves performing multi-label classification with 10,000 distinct classes, utilising single-label positive training data marked by severe class imbalance and an exceptionally high number of categories. To make accurate predictions, the system must use the various available predictors, including satellite imagery and time-series data, climate time-series data, and rasterised environmental information including land cover, human footprint, bioclimatic factors, and soil variables. It is important to note that the majority of the ground truth training data consists of presence-only information sourced from citizen science initiatives without a standardised sampling protocol.
🗓️ Final submission deadline May 17, 2023
💾 Training Set: 5M plant occurrences in Europe (single-label)
💾 Test Set: 20k plots with all present species (multi-label)
New Video: Satellite imagery & AI for Social Good
In this new video I caught up with Minh Trinh and gave a presentation on the multiple applications of AI and satellite imagery for social good. These applications include disaster response & risk reduction, disease outbreak monitoring, monitoring deforestation, wildlife conservation, urban planning and more.
FireRisk dataset

FireRisk is a new remote sensing dataset for fire risk assessment with benchmarks using supervised and self-supervised learning
Lightning 2.0: Fast, Flexible, Stable

PyTorch Lightning is a popular deep learning framework that removes much of the boilerplate code required for training PyTorch models, and enables training across multiple GPU’s. It is now known as Lightning and just had a major 2.0 release 🎉🎉. Highlights include a commitment to backward compatibility in the 2.0 series, simplified abstraction layers, and the introduction of a new API called Fabric which enables scaling any PyTorch model with just a few lines of code.
Google Dataset Search

Google Dataset search just got relaunched with better metadata and search capabilities. Datasets are indexed from Kaggle, Zenodo and other major platforms, and instructions are provided on how to publish your own dataset in a way that makes it discoverable. Credit to Yuri Shlyakhter for highlighting this news on the satellite-image-deep-learning Discord
Discord update 🗣️

The satellite-image-deep-learning Discord server is a free-to-join chat platform similar to Slack. I am delighted to report that we now have almost 300 people on the server, and it is becoming established as a place for people in our community to connect, exchange ideas, and collaborate on projects. I hope to see you there!
Poll
In the last poll I asked how often people contribute to open source, and 38% said ‘Occasionally (yearly)’, and only 18% said ‘Frequently (monthly)’. To my surprise 32% said they ‘Don’t feel able’ to contribute to open source, and I would like to dig into that category more deeply. If you don’t feel able to contribute, can you indicate the reason?