
New Discoveries #29
Open Buildings 2.5D Temporal Dataset, Detecting Looted Archaeological Sites from Satellite Image Time Series, Global Prediction of Aboveground Biomass, and more

Welcome to the 29th edition of the newsletter! After a summer break, I’m excited to be back, and thrilled to announce that the newsletter has reached over 11,110 subscribers 🔥. A huge thank you for your continued support 🙏
In this edition, I explore two cutting-edge techniques that are advancing machine learning in remote sensing: training on time-series data and predicting multiple tasks simultaneously. These methods allow models to extract richer information and scale more effectively for large applications. The first technique highlights how combining lower-resolution satellite images over time can enhance spatial detail, while the second demonstrates how multi-task learning boosts model efficiency and accuracy. Together, these innovative approaches are shaping the future of scalable, high-performance models. I hope you enjoy this edition!
Open Buildings 2.5D Temporal Dataset

Mapping buildings and roads automatically typically requires high-resolution imagery, which is both expensive and often infrequently available. In this work from Google Research, sequences of Sentinel-2 images at 10 m resolution are used to generate 50 cm resolution building and road segmentation masks. This is achieved by training a student model on a stack of Sentinel-2 images to replicate the predictions of a teacher model trained on a single high-resolution image with human-created annotations. The Sentinel-2-based building segmentation predictions achieve a mean Intersection over Union (mIoU) of 79.0%, compared to the high-resolution teacher’s 85.5% mIoU. This accuracy level was shown to be equivalent to the performance of a high-resolution model using 4 m resolution imagery, showcasing the technique’s ability to enhance segmentation from lower-resolution data.
The success of this approach is driven by two key factors. First, the use of time-series data allows for greater spatial detail than any single low-resolution frame can offer. Sentinel-2 images, captured every 2 to 5 days, provide frequent revisits over the same area, and because of small spatial shifts between frames caused by atmospheric disturbances and sensor alignment, each image captures slightly different information about the same 10 m² area. When these multiple images are fused using the HighResNet model, the subtle differences between frames enable the reconstruction of finer detail, resulting in much higher-resolution predictions. This method shows that even though individual images have lower resolution, their combined temporal richness and global coverage allow them to produce results comparable to high-resolution imagery. HighResNet achieves this by training end-to-end, directly predicting high-resolution outputs without an intermediate super-resolution step, making the process both efficient and scalable for large areas.

Second, multi-task learning significantly enhances the model’s overall performance. Beyond building and road segmentation, the model simultaneously predicts building centroids (useful for counting buildings), building heights, and a super-resolution grayscale image. This multi-task setup allows the model to leverage insights across tasks, improving accuracy and robustness. For instance, predicting building centroids helps the model better understand the spatial layout of structures, which improves the precision of segmentation. Similarly, learning to estimate building heights provides additional geometric context that refines the segmentation process. By training the model to handle related tasks in parallel, it learns to extract richer and more comprehensive spatial features from the same input data. The model’s success across auxiliary tasks, such as achieving an R² of 0.91 in building counts and a mean absolute error of 1.5 meters in height estimation, further demonstrates the power of this multi-task approach.
This work demonstrates how combining temporally rich, lower-resolution data with multi-task learning can achieve high-resolution results, even in areas where high-resolution imagery is unavailable or infrequent. This method opens new possibilities for automated mapping across vast regions, making it a powerful tool for remote sensing applications.
DAFA-LS: Detecting Looted Archaeological Sites from Satellite Image Time Series

Archaeological sites are not just remnants of past civilisations; they are vital to understanding human history. Unfortunately, in conflict-ridden regions like Afghanistan, looting threatens the preservation of these sites. To address this, researchers have developed DAFA-LS, a groundbreaking dataset designed to detect looting via satellite imagery.
The DAFA-LS dataset includes over 55,000 images captured monthly over eight years, documenting 675 archaeological sites in Afghanistan, 135 of which were looted during the study period. This initiative presents a unique challenge due to the limited amount of training data, class imbalance, and the subtlety of relevant changes over time.
The paper explores three different approaches for detecting looting: single-frame image analysis, pixel-based time series analysis, and whole-image time series methods. The results show that foundation models, particularly the DOFA model, provide significant performance boosts. Whole-image methods that analyze full satellite image sequences vastly outperform pixel-wise techniques, highlighting the importance of capturing spatial information across time.
This work is a major step forward in using satellite technology to protect global heritage sites, and the DAFA-LS dataset is set to play a key role in further research and development in this critical area.
Global Prediction of Aboveground Biomass, Canopy Height and Cover

In a recent study addressing the global assessment of aboveground biomass density (AGBD), canopy height (CH), and canopy cover (CC), a novel deep learning approach was introduced to overcome the challenges posed by sparse ground truth data from space-borne LiDAR instruments like GEDI. Traditional models often struggle with overfitting when trained on sparse datasets, which limits their ability to generalise over large areas. To address this, the researchers at Descartes Labs (now part of EarthDaily) developed a unified model capable of predicting AGBD, CH, and CC from multi-sensor satellite imagery, including Sentinel-1, Sentinel-2, and digital elevation models. The model uses a convolutional neural network (CNN) with a feature pyramid network (FPN) architecture, allowing for the simultaneous prediction of multiple variables, which improves efficiency for global-scale carbon monitoring.

A key innovation in this study is the handling of sparse labels using a student-teacher framework. Instead of evaluating the loss function only on pixels with ground truth values, which can lead to overfitting, the authors employ a teacher network to generate soft labels for the student network to learn from. This iterative process helps the model build a continuous target map, gradually improving predictions while minimising overfitting. The use of soft labels, which are weighted based on spectral similarity during the early phases of training, helps guide the model when ground truth data is sparse, leading to a more homogeneous output. The model achieved strong results, outperforming state-of-the-art models for AGBD and CH estimation, and demonstrated its robustness across third-party datasets without additional fine-tuning.
This approach not only addresses the scalability of carbon stock assessments but also enhances the ability to generate accurate predictions over diverse ecosystems. By leveraging global datasets and machine learning techniques, this model provides an efficient and scalable solution for monitoring aboveground biomass and related variables, crucial for climate impact analysis and carbon accounting.
📖 Paper
Searching an aerial photo with text queries
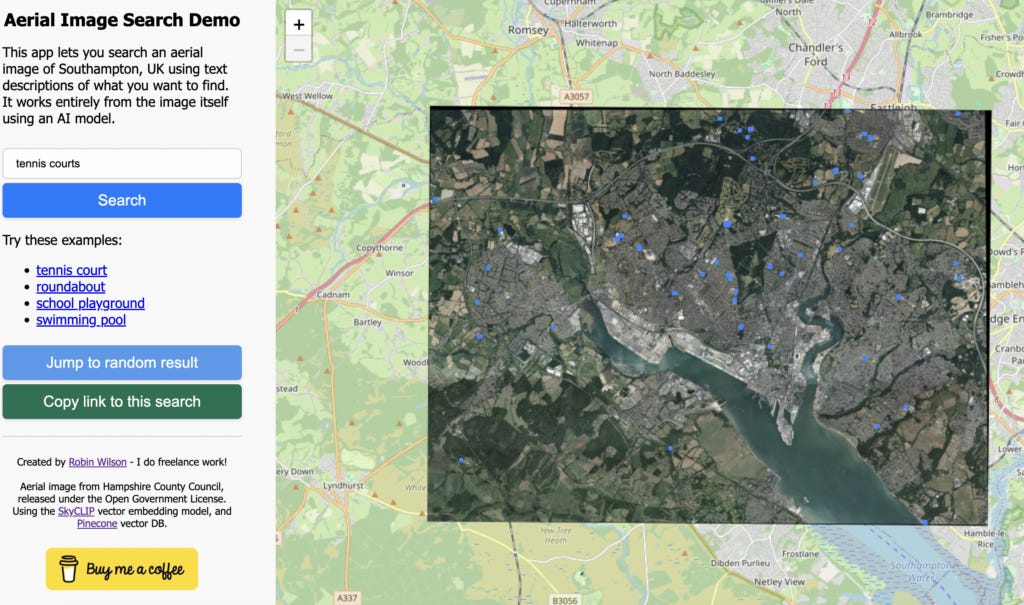
In a recent blog post, Robin Wilson introduces a demo web app that allows users to search an aerial photo using text queries like "roundabout" or "ship." The app works by converting both the image and text queries into vector embeddings, enabling a similarity search. Robin uses the SkyCLIP model, which was trained on millions of remote sensing image-text pairs, to generate these embeddings. The process involves splitting the aerial image into smaller chunks, calculating embeddings for each, and then comparing them to text query embeddings using cosine similarity. The search results are displayed on a Leaflet web map, with the backend supported by the Pinecone vector database.
scikit-eo: A Comprehensive Python Package for Remote Sensing Data Analysis

The scikit-eo Python package offers a powerful solution for remote sensing data analysis, supporting both classical machine learning algorithms like Random Forest and advanced deep learning techniques. It provides tools that simplify tasks such as land cover classification, forest degradation mapping, and image fusion, enabling users to perform complex analyses with minimal coding. Its integration with popular Python libraries like NumPy and Pandas make it versatile and easy to install via PyPI or GitHub. Whether you're applying traditional methods or exploring deep learning, scikit-eo provides a flexible, efficient framework for remote sensing projects.
TorchGeo 0.6.0

The mission behind TorchGeo is to bridge the gap between machine learning and geospatial data analysis. TorchGeo 0.6.0 introduces 18 new datasets, 15 new datamodules, and 27 pre-trained models, marking 11 months of contributions from 23 developers. This update brings multimodal foundation models capable of handling imagery from any satellite or sensor, including RGB, SAR, MSI, and HSI data, thanks to a novel wavelength-based encoder.
TorchGeo 0.6 also strengthens its integration with Lightning AI, adding seamless support for Lightning Studios ⚡, a powerful alternative to Google Colab. With built-in reproducible environments, VS Code, terminal support, and scalable GPU capabilities, you can easily experiment with TorchGeo’s tutorials on both Lightning Studios and Colab, without the need for specialised hardware.
Good to discover your articles here